Fake News Classification using LSTMs

Classifying news articles as real or fake using Natural Language Processing techniques.
With the advent of the internet, the world has never been so informed. News can be shared across the globe within seconds through online sources such at news websites, blog posts, twitter etc. But, the grim reality is that there is a lot of misinformation and disinformation on the internet. Most recently, during the peak of the COVID-19 pandemic, misinformatino about vaccines spread like wildfire. Why don’t we use NLP to combat this?
1. The Dataset
The dataset consists of news article gathers from some of the major sources in the United States such as The Washington Post, Reuters, New York Times, etc. These articles cover the following topics:
- Politics
- World News
- Government News
- Middle-east News
The structure of the dataset is:
- title: Title of the news article
- text: The content of the article (whole)
- subject: One of the above mentioned topics
- date: Date of publish
- isfake: A binary varible where 1 is Fake and 0 is Real
2. Data Cleaning
Each news article from the corpus was stripped down by removing the stopwords. The list of stopwords were obtained from the nltk and the gensim libraries.
|
|
The news article was tokenized and each token was checked against the list of stopwords. The remaining tokens were stored in a list and then joined to form a clean article.
|
|
3. Exploratory Data Analysis
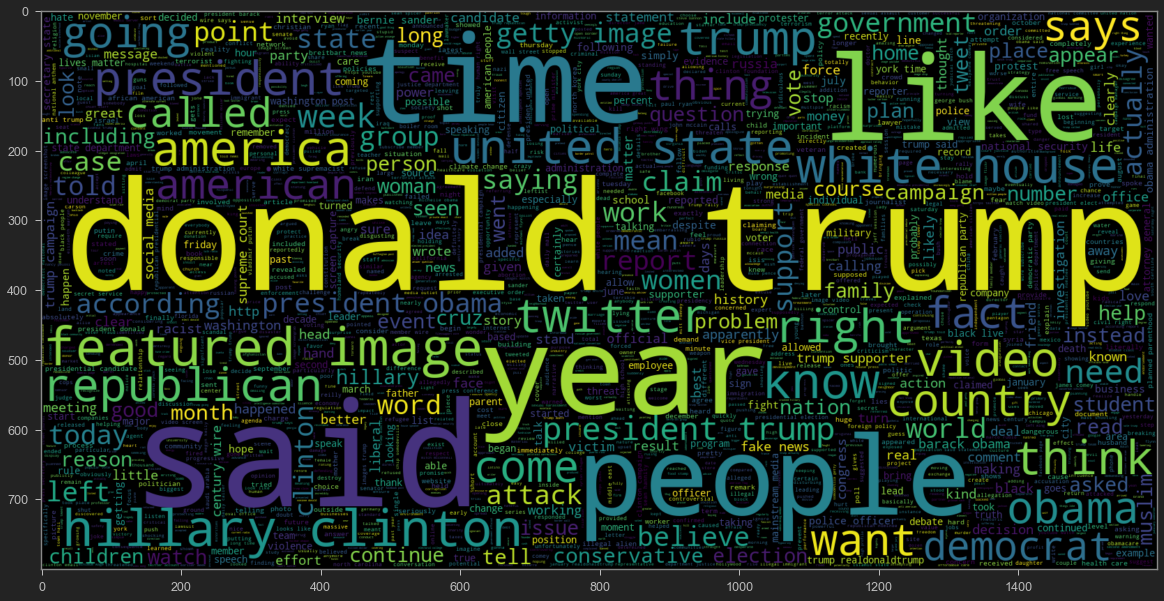
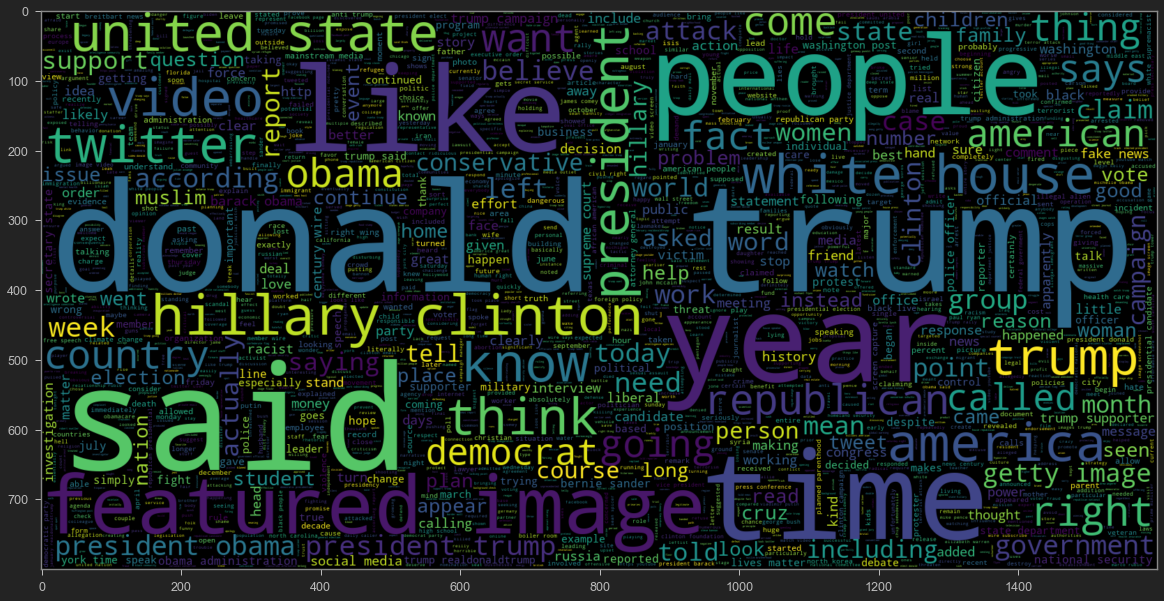
To get a better understanding of the dataset, WordCloud was used to see the most frequently used terms in the fake and real news articles.
Word Cloud for fake news
|
|
Word Cloud for real news
|
|
4. Preparing data by tokenization and padding
Once the data is cleaned, I created train-test splits using train_test_split from the sklearn library. Then a Tokenizer from the nltk library was used to generate sequences of tokenized words.
|
|
Next, each sequence had to be padded to the maximum length of article in the news corpus.
|
|
5. Building the Model
Now for the fun part!
The model I used for this task was a Bidirectional LSTM with 128 units. I had to use a bidirectional model because the length of these articles are quite long and so I wanted to capture long term dependencies from the future and the past. To train the model I used the TensorFlow framework. An Embedding layer was added before the BiLSTM layer to convert the sequences into Embeddings for the model to train on. Since this is a binary classification problem, the output layer has one unit with a sigmoid activation. The adam optimizer was used and the loss function was set to binary_crossentropy.
Code
|
|
6. Training and Performance
The model was trained for 2 epochs with a validation split of 0.1 and a batch_size of 64. The trained model was then evaluated on the test set by obtaining the sigmoid outputs. If the value is greater than 0.5, classify as fake.
Code
|
|
7. Results
With a test accuracy of 99.6%, this model does a great job at detecting if a news article is real or fake.